コンピューターの使い方
1 はじめに
2 プレインテキストのすすめ
- 紙に書いた論文、フィールドノーツ(「紙媒体」)とコンピューターのデー タ(「電子媒体」)を比較してみよう
- 20年後、30年後を考えよう
- 紙媒体はそれを失くしていない限り問題ない(→ 筆記用 具の問題がある)そのまま読むことができる
- 紙媒体の欠点は検索のむずかしさだ
2.1 秘密フォーマットと透明なフォーマット
- 電子媒体として保存する時はどうだろうか?
- たとえば MSWord は私企業の秘密フォーマットである
- MicroSoft があなたのデータの「読む」力を握っているのだ
- プレーンテキストのフォーマットは透明です
2.2 フォーマットとは
- コンピューターの中のデータはビットの列です
- それを「どう読むか」がファイルフォーマットです
- プレインテキストにももちろん「どう読むか」が存在 しますが
- それは公で単純で、ほぼ変更されることはないでしょう
- それゆえ、ほぼ紙媒体のようなモノ(「暗号表を通さ ずに読める」)と考えてかまいません
- プレインテキストは不滅です
3 Linux のすすめ
- コンピューターに興味がある人だけへのアドバイスで すが・・・
- Linux を使うことを勧めます
- (Windows ではなく)(Apple は問題外です)
- 「好き」でないと駄目です
3.1 Unix の哲学
- テキストを入力してテキストを出力する小さなプログ
ラムが沢山用意されています
sedawk- などなど
- それで足りなければ自分でプログラムを作るためのプ
ログラミング環境も整っています
perlpythonruby
- テキストを作るのがエディタです
emacsが有名ですemacsは巨大な環境です
- (Unix を祖先とする)Linux という環境はテキストを基本に 考えられています
- プログラムは標準入力からテキストを受け取り、
- それを加工して
- 標準出力へと(たいていの場合)テキストとして吐き 出します(下の図を見てください)

- たいていの処理はこのような Input/Output がいくつ も繰り返される連鎖となります
- 下の図のようになります
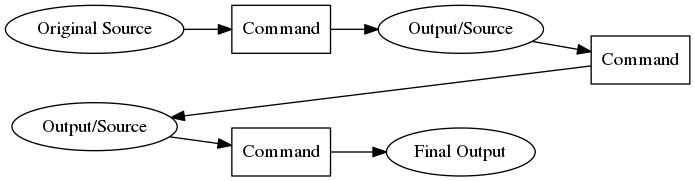
3.2 Make
- この流れを統括するのが
makeと呼ばれるプログラ ムです - まず ``Original Source'' から ``Final
Output'' を作り出す手順を(拡張子に焦点をあてて、
一般化した上で)ファイル(
Makefileと呼ばれて います)に書いておきます(手作業です) - これさえあれば、あとはそのディレクトリ(フォルダ)
で
makeと打てばおわりです makeはTimestamp をみて最小限の手順でさきほどの連鎖を自 動で行なってくれます
4 フィールドノーツ、読書ノーツの取りかた
- 電子バージョンです
- さきほどの紙の情報を入力します
4.1 ノートを入力する
- 「入口は一つ」の原則
- わたしの場合、日誌 (log) になるべく全てを記入し ています
- 一日毎に一つのファイルを作り、それに log だけで なく、読書ノーツ、フィールドノーツを入力します
- その他に天気、出来事、値段、食事、自分の体の状況 など時間順に何でも書き 込みます
- (「日記」ではなく、「日誌」です)
- これらのエントリーは後に(プログラムを使って)バラバラ にして、全文検索のためのインデックスを作成します
- さきほどの紙媒体のあるデータを入力してみましょう

- フィールドノーツのフォーマットは次のようになります
_FLD_DATA( {ママ・オビのナラ(兄弟)が結婚する},
{S-968-18}, {S-968}, {18},
{2014-08-19}, {2015-08-01 09:33:52}, {[2015-08-01]},
{Fine}, {Satoshi }, {Conversation},
{Yaan/Kekadori}, {Oli}, {Yaan},
{anth}, {kinship/marriage}, {bridewealth}, {mtrl},
{ hypo },
{ q }, {cf},
{ nt },
{
_PRE({
+----+
| |
m m Malo m Gerhi m
AndE | Mari[1]| |
Kapo +---+ +--+ |
| | | |
f == m f === m Tinus
Foru |
m Obi
})
_P ママ・オビ (Mama Obi) のナラ(兄弟) _G(nara)は
フォル (Foru) といい、
パウ・ンガッダ (Paungadha)の
マリ (Mari) (亡くなっている)の子供である。
_PRE({
m Gati
|
+------------+
| | |
m m m
Mari Petu Toni
})
},
{Ende}, {kinship/events})
- この一つのデータエントリー全体は
_FLD_DATA(...)という塊で - そこに
{...}という形の要素がいくつかある、と いう構造をとっています _FLD_DATA({}, {}, {},...)という構造です
- 最初の要素がタイトル、二番目が id、三番目がノー トブックの番号、四番目がページ
- 五、六、七番目がデータの日付、入力の日付、最新修 正の日付・・・
- このデータを含むある一日 のファイル(2014-08-19) の全体は つぎ (動画) の ようになります
- めんどくさそうですが、emacs でそれらの入力のため
の関数 (
yaml-fnotes-entry)を作ってあるので、問題はありません - その関数の一部だけを
(defun yaml-fnotes-entry ()
"Filed notes entry made easy a la ShoeBox"
(interactive "*")
(let (title book_no page da ref de rscr type loc
part inf anth cat reg mtrl kwd)
;;; mtrl hypo q cf nt dt
(save-excursion
(if (re-search-backward "_FNN(\\([SE]-*[0-9]*\\))" 0 t)
(if (match-beginning 1)
(setq book_no-default
(buffer-substring (match-beginning 1) (match-end 1)))
)))
- その関数を使っての入力の次第は次のようになります
- データ入力の様子 (動画)
- 「入口は一つ」の意味が分かりましたか?
- なお、タイトルは必ず主語述語のある 文 にするよ うに!「何々について」というのは ペケ です!
4.2 全文検索
- 出口はいっぱいあります
- データは「検索できてなんぼ」です。検索の準備をしましょう。
- まずこれらの数年分のファイルから
FLD_DATA(読 書ノーツの場合はLIB_DATA)の部分だけを抜きだ して、一つひとつHTML化します - 【ね!】対象がプレインテキストだから、そのような 作業をするプログラムも簡単に書けます
- 置き場所は
Dropboxと同期するディレクトリ(フォ ルダ)にしています(意味はあとで分かります)
- つづいて、そのディレクトリのファイルを対象に全文
検索をかけます(わたしの場合は
namazuを使って います) - できあがったインデックスは別の(これもまた
Dropboxと同期させている)ディレクトリに置きま す - もちろん、
makeで (terminal でmakeと打つ)すべて自動的に行ないます - これで準備完了です。いつでも検索ができるようにな ります
4.3 モバイル
- 同じことがモバイル環境 (Android) でも可能です
- まず Dropsync (Google Play へのリンクです)で、
Dropboxにあるデータとインデックスとを Android マシンと同期させます - つぎに namazudroid (Google Play へのリンクです)をインストールして、設定しま す
- これで準備完了。いつでもどこでも検索ができるよう になります
- 次のページからその結果をお見せしましょう






5 役に立つプログラム
- graphviz 図形をプログラムで書く
- make
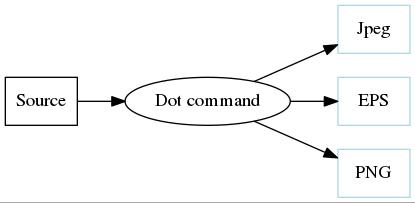
5.2 簡単なプログラム
まず簡単なプログラムを見てみましょう。
次のようファイルをエディタで作ります。
foo.dot としましょう。
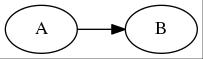
digraph {
A->B;
}
続いてつぎのように(ターミナルに)打ちます。
-Tjpg は「 jpg のフォーマットにして」という
オプション(-T) で、
">" は出力を向ける先です。
これがなければ標準出力が選ばれます。
dot -Tjpg foo.dot -o foo.jpg
こんな図形 (foo.jpg) がアウトプットされます。
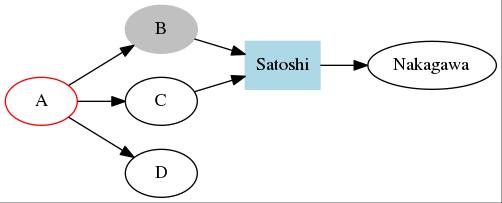
5.3 もうすこし複雑なプログラム
もう少し複雑なプログラムを作ってみましょう。
digraph {
rankdir = LR;
A->B->Satoshi->Nakagawa;
A->C;
C->Satoshi;
A->D;
A [color=red];
B [shape=box,style=filled,color=gray]
}
- いかがですか?
- なかなかだとわたしは思うのですが。
- ちなみに、
今回のプレゼンテーションのすべての
ダイアグラムは
dot/graphvizで 書かれています。